pipeline parallelism
流水线并行的核心思想是:在模型并行的基础上,进一步引入数据并行的办法,即把原先的数据再划分成若干个batch,送入GPU进行训练。
model parallelism
当你有一个单卡装不下的大模型时,一个直接的解决办法是,把模型隔成不同的层,每一层都放到一块GPU上:
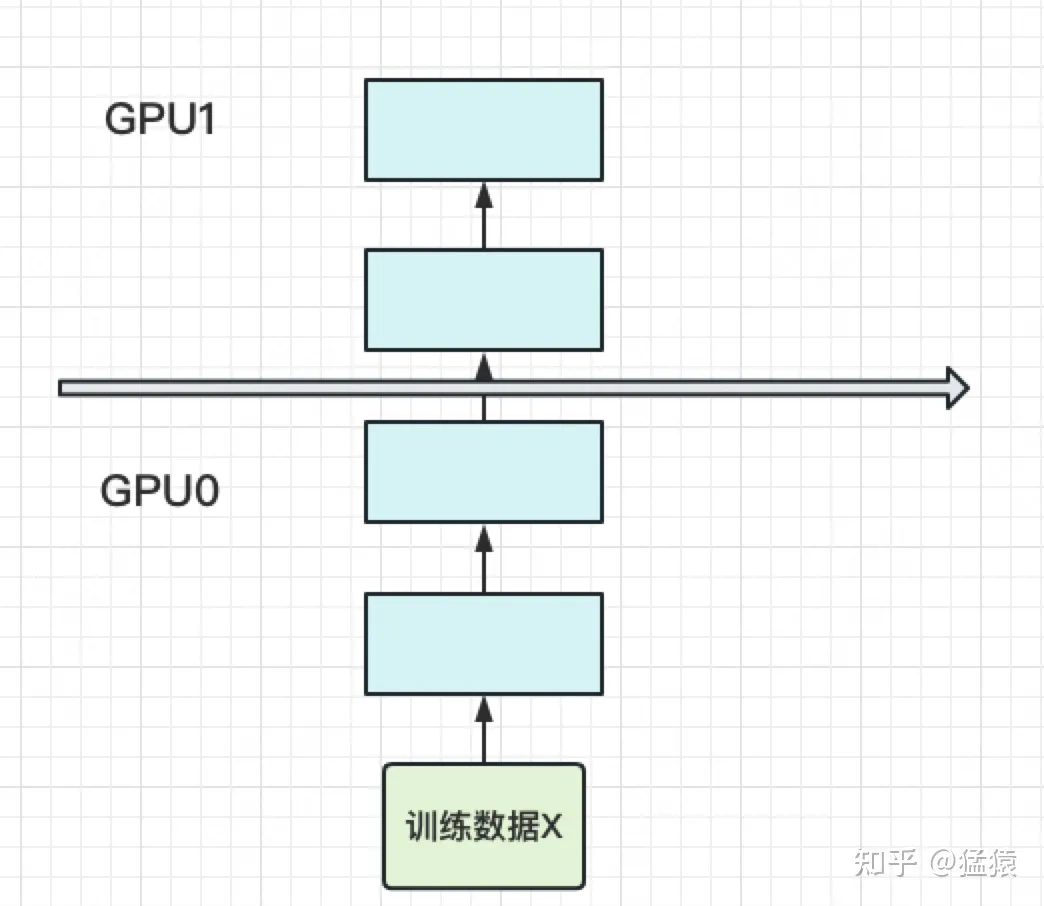
这样,模型的一个 epoch 的计算过程可以表示为:(每一行表示一个GPU。每一列表示timestep)
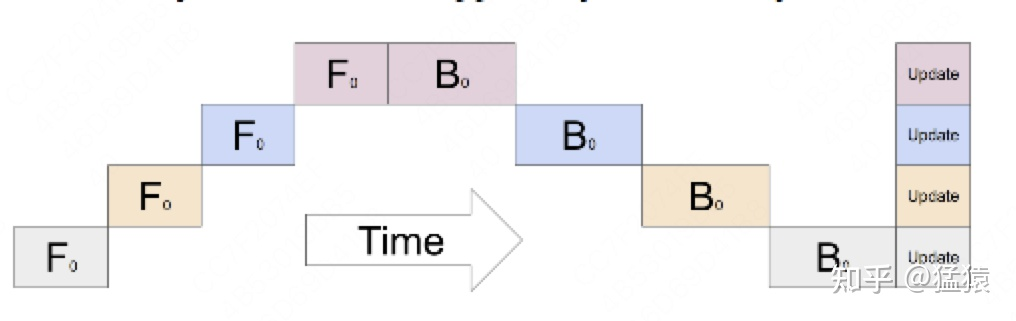
显然这样会导致 GPU利用度不够(上图中存在很多空白) 和 中间结果占据大量内存(每次 backward 都要用到每一层的中间结果
因此,我们需要在模型并行的基础上引入数据并行,将 mini-batch 切分为 micro-batch,这就是 Gpipe:
切分 micro-batch
在模型并行的基础上,进一步引入数据并行的办法,即把原先的数据再划分成若干个batch,送入GPU进行训练。未划分前的数据,叫mini-batch。在mini-batch上再划分的数据,叫micro-batch。
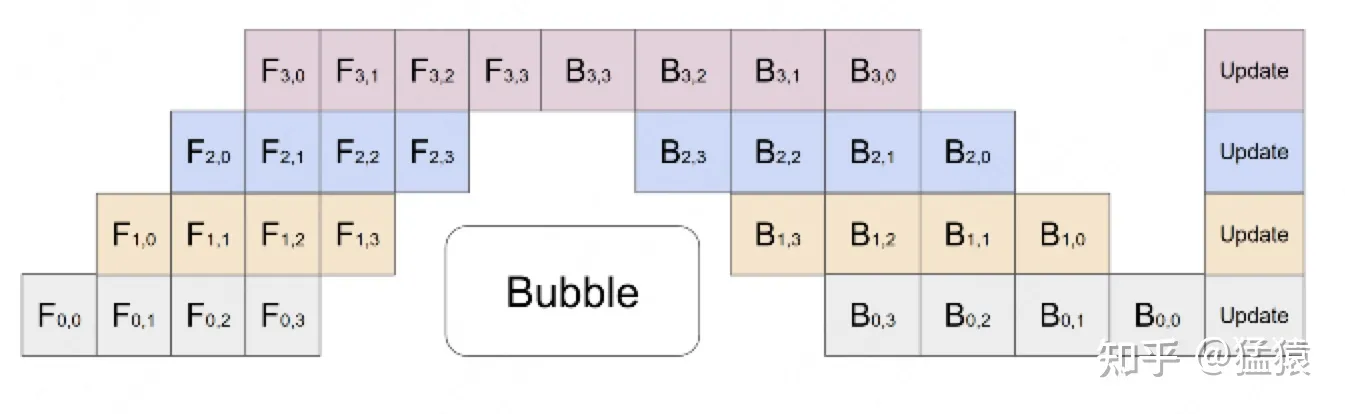
第一个下标表示GPU编号(也表示神经网络的层数),第二个下标表示 micro-batch 编号
通过这种方式解决了 GPU利用度不够 的问题
re-materialization(active checkpoint)
随着模型的增加,每块GPU中存储的中间结果也会越大。对此,Gpipe采用了一种非常简单粗暴但有效的办法:用时间换空间,在论文里,这种方法被命名为re-materalization,后人也称其为active checkpoint。
具体来说,就是几乎不存中间结果,等到backward的时候,再重新算一遍forward。
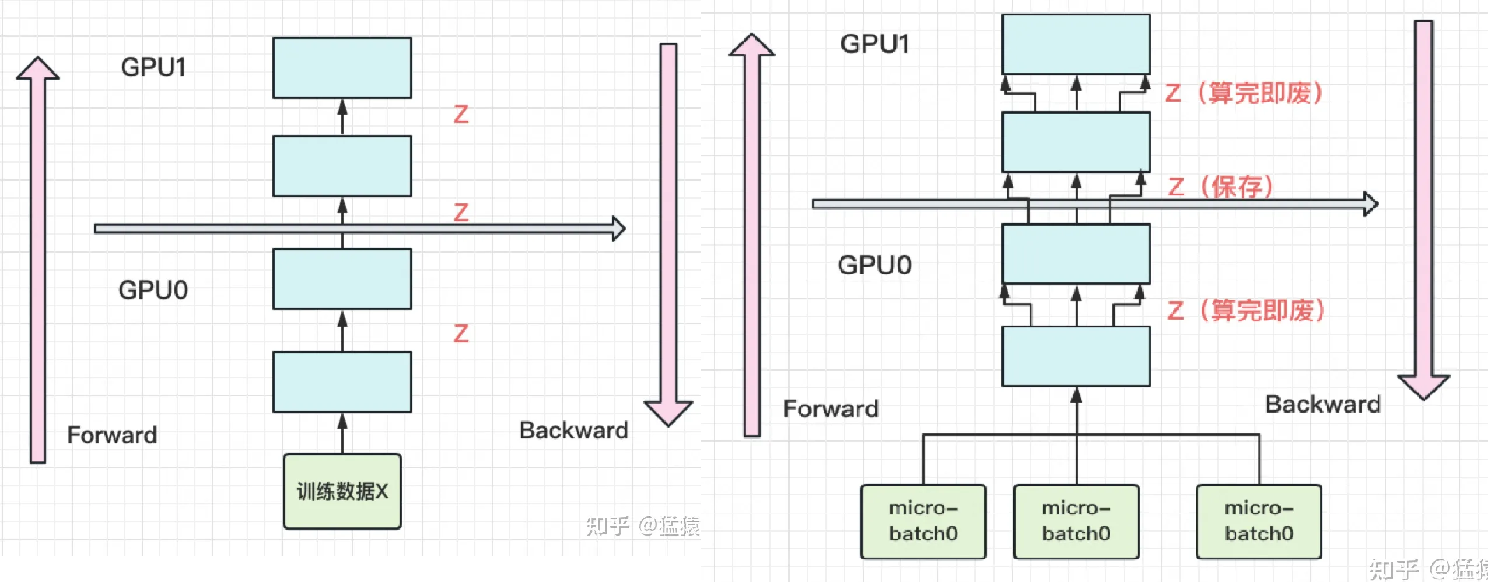
每块GPU上,我们只保存来自上一块的最后一层输入z,其余的中间结果我们算完就废。等到backward的时候再由保存下来的z重新进行forward来算出。
(左图为改进前,右图为改进后)
关于 batch normalization
在micro-batch的划分下,我们在计算 Batch Normalization 时会有影响。Gpipe的方法是,在训练时计算和运用的是micro-batch里的均值和方差,但同时持续追踪全部mini-batch的移动平均和方差,以便在测试阶段进行使用。Layer Normalization则不受影响
Gpipe 下消耗时间分布
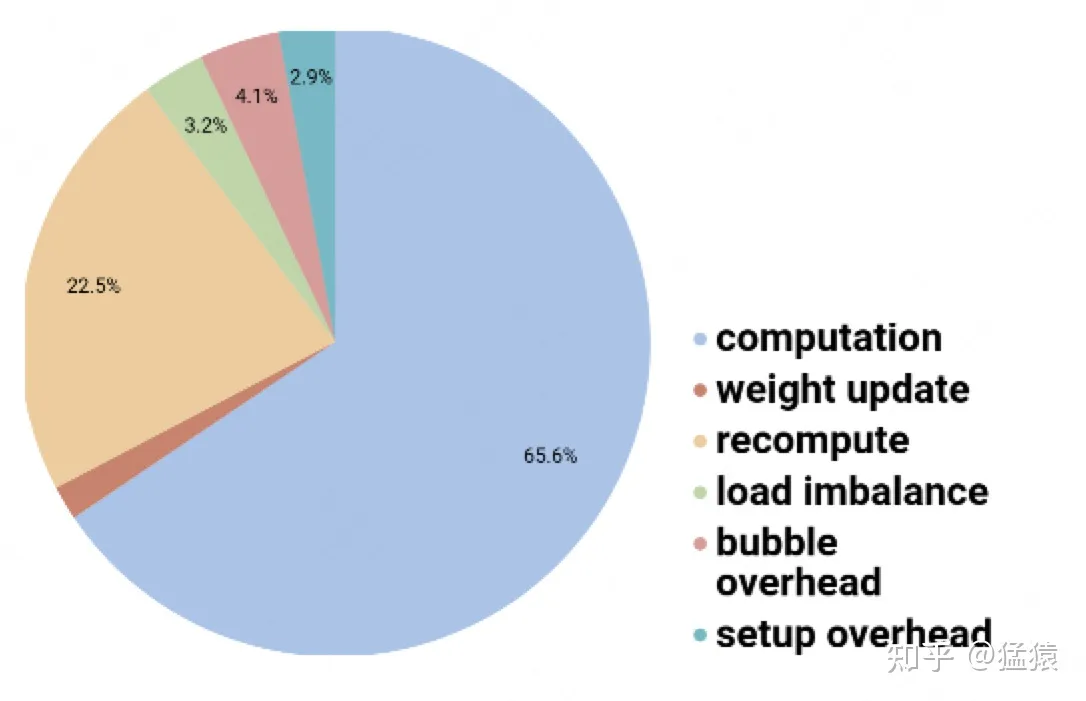
而 PipeDream 在 Gpipe 的基础上进一步优化了 pipeline flush,在进行前向传播的同时进行反向传播(Gpipe 是等所有前向传播完成后再进行反向传播)。当然,在进行前向传播的同时进行反向传播会对模型的精度产生相当大影响(因为前向传播和反向传播用的 weights 不一样,会改变神经网络的数学构造)。因此 PIpeDream 采用了缓存 weights 的策略。
PipeDream核心在于解决两个问题:
- 对于一个给定的模型与分布式系统,如何划分任务(即哪个节点负责哪些layer,某些layer是数据并行还是模型并行)
- 对于流水线模型,如何避免流水线本身带来的训练的问题。
如何划分任务
简单的说就是一个动态规划模型:把M层的网络分给N个节点算,最短的时间要么是M-1层分给N-1个节点算,或者M-1层分给N-2个节点算,或者blabla
方程如下
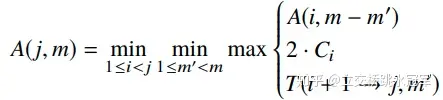
具体步骤:
- 对模型进行profiling,得到
- 每层layer前向和后向的计算时间
- 每层layer的输出的大小
- 每层layer参数的大小
- 根据profiling的结果,使用动态规划对模型进行划分,将模型划分为不同的stage,以及每个stage的replication(数据并行)数。
如何解决精度问题
目前最主流的分布式深度学习框架用的都是sync SGD,就是每轮iteration结束之后所有机器统一传输一下grad,以此来更新自己的weights从而进行下一轮训练。
坏处是每轮都得等最慢的机器做完
好处是这样彻底模拟了单节点的训练模式,精度最高
但是 pipedream 显然不能使用 sync SGD。
weight stashing
我们来看一下Machine2,发现当他在forward算第5个batch(图中第二行深蓝色的5)的时候,它用的weights是更新两次的(即前面浅绿色的1和2更新了两次参数),而当backward算第5个batch(图作用第二行浅绿色的5)时,用到的weights是更新了4次的(即前面浅绿色的1,2,3,4)。无疑这种做法彻底改变了单节点深度学习的很多假设,自然会降低训练的效果(准确率下降)(出现这种情况有一个假设就是梯度的计算依赖weights,如果是类似relu, max pool这样的,就不会出现这种问题)
针对于这个问题,作者提出了Weight Stashing,思路很简单,就是每个node多备份几个版本的weights,forward用哪个weights算的,backward就还用它
Vertical Sync

显然还是有一些差距:我们现在fwd的时候,经过的每一层计算的时候,它们被更新了不同的次数,有没有什么办法可以更进一步?
也是有的,那就是每次forward的时候,都按照更新最少的那些weights来算。举个例子,我们在算第5个batch的时候(图中深蓝5),Machine1算的时候,weight自然就是更新了一次的。它算完得到的output扔给Machine2的时候,Machine2也用只更新了一次的weight算(就好像浅绿色的2没有用),算完得到的output扔给Machine3,Machine3也用只更新了一次的算(就好像浅绿色的2,3没有用)
不过作者也坦言,这个优化提升效果不太大,最重要的还是第一个优化(即fwd,bwd用同样的weights
Work Scheduling
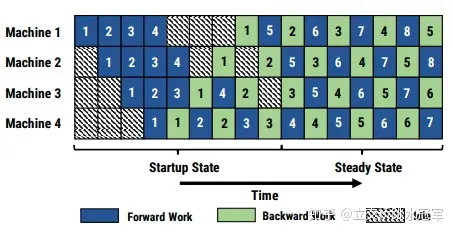
- startup state 在训练开始的阶段,输入的stage的先读入足够多batch的数据,以保证pipeline在稳定阶段时,各个设备上都有相应的工作
- 采用 1F1B(one-forward-one-backward) 的调度模式,即每台机器上交替的进行前向后向计算。这种方案可以使得每个GPU上都会有一个batch的数据正在被处理,整个pipeline是比较均衡的,同时也能确保以固定周期执行每个stage上的参数更新。
- 对于使用数据并行的stage,采用 round-robin 的方式将任务分配在各个设备上,需要保证一个batch的数据在前向和后向发生在同一台机器上,这套策略称为 1F1B-RR(one-forward-noe-backward-round-robin)。

https://zhuanlan.zhihu.com/p/336849279
https://zhuanlan.zhihu.com/p/113416860
参考博客:图解大模型训练之:流水线并行(Pipeline Parallelism),以Gpipe为例 - 知乎 (zhihu.com)